
WHERE IN 包含大量的元素的查询优化
应用端反馈一个涉及功能菜单渲染的基础SQL查询时间超过7秒,原因是where x in (上千个的元素),通过Presto观察,发现这个SQL的查询的时间90%花在了执行计划的解析上,真正查询时间反而很快。通过删减 where in 中的元素,发现SQL就快了很多,也证实了,问题的根本原因在in 元素集合过多
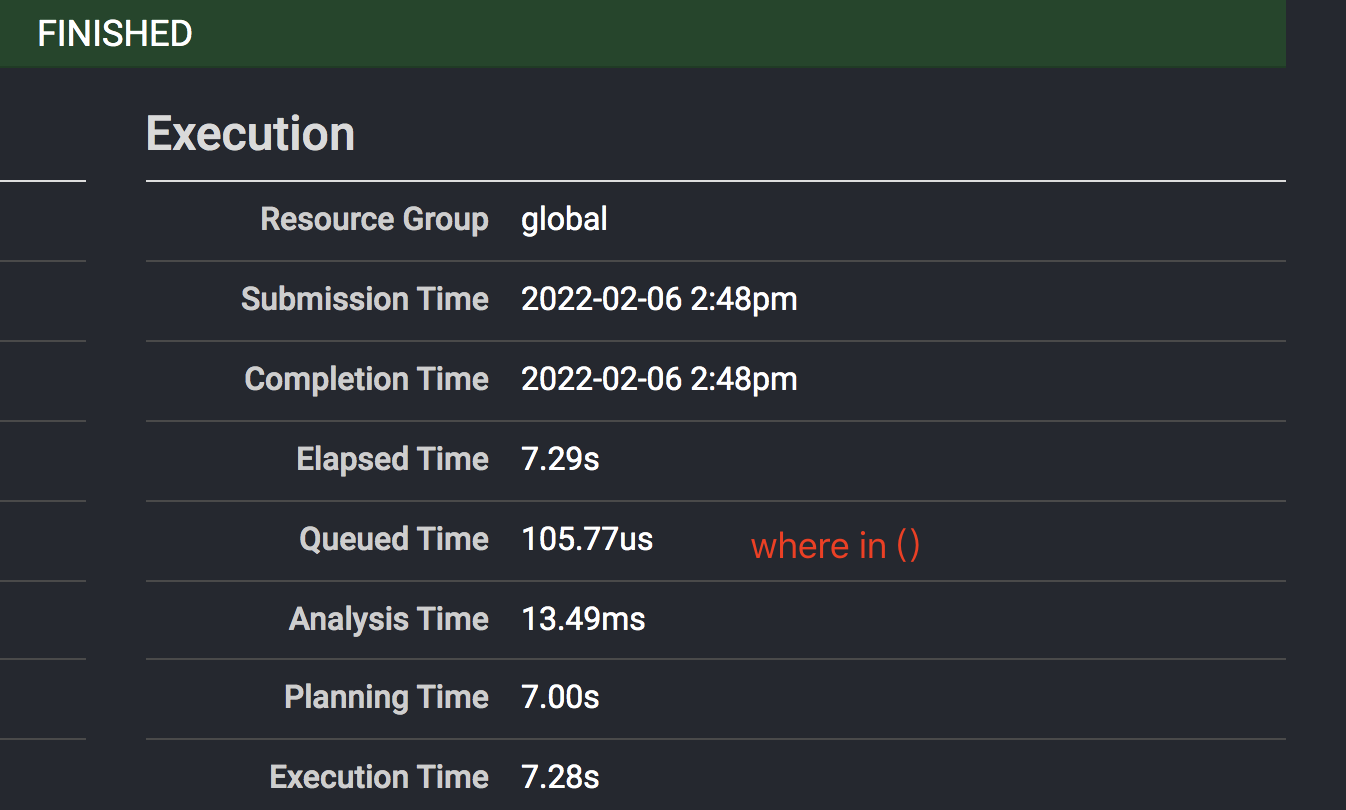
然后询问了下使用场景,是否可以减少元素,比如连续的元素改成 x < id < y 这种范围条件。答复是不行,是离散的,不是连续的,也无法减少元素
只能换一种sql 写法,当时第一时间想自定义一个RoaringBitMap(RBM)的contains 函数来测试,但是发现presto有一个数组的contains方法,因为RBM如果元素个数小于四千个内部也是数组,于是改写了sql,先试试 数组的contains()函数
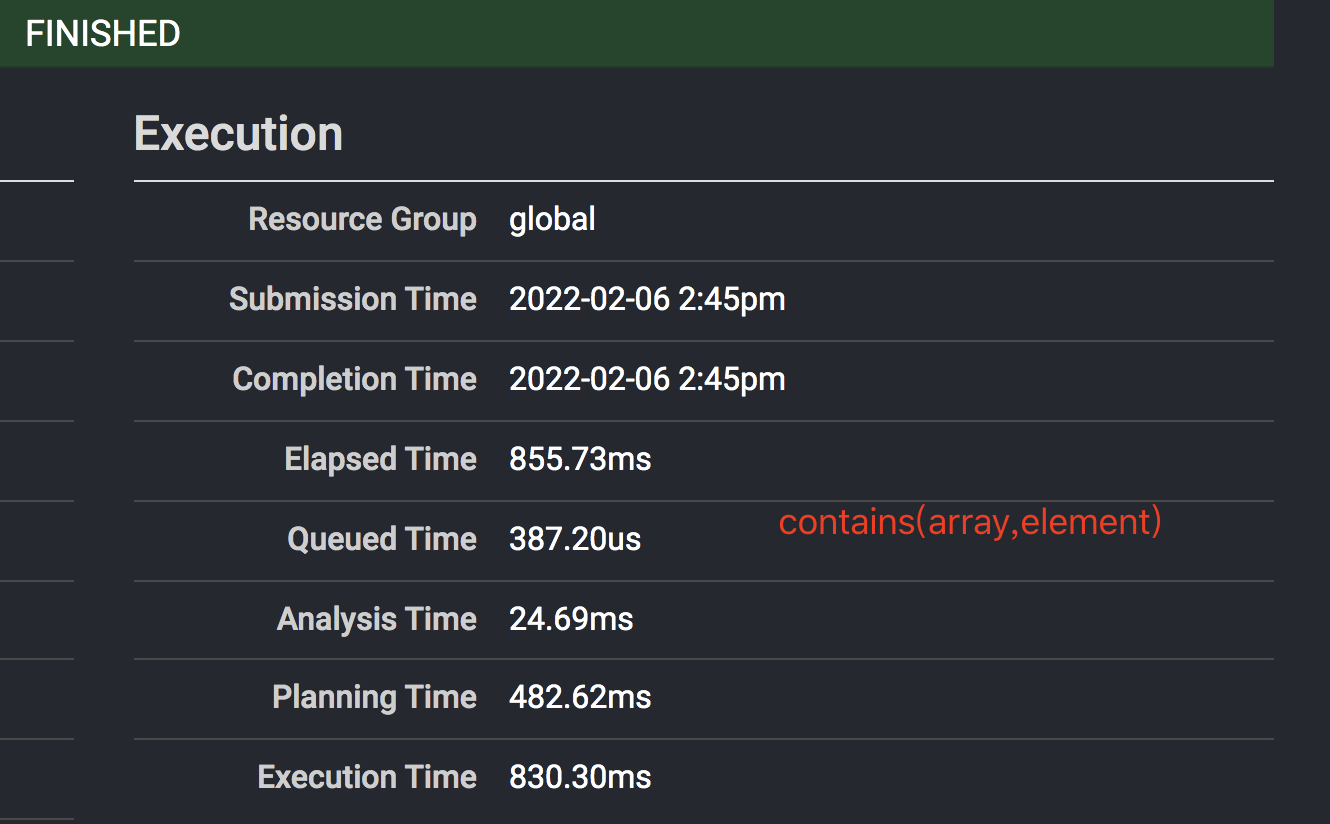
where in 元素个数大概在2500个时,contains(Array[],element)的写法比 where x in (elements) 快了近10倍
后续加了rbmContains()函数,测试和 contains(Array[],element) 差不多,稍微快一点,rbmContains 优势应该体现在4K 以上的元素,rbm除了判断contains 还有其他很多用途,后续再补一篇RoaringBitmap 的文章
由于在拼SQL时,可以提前查询出元素数组个数,所以当元素个数小于50时,就用 where in ,大于50 小于4000 用 数组的contains,超过4000 就用rbmContains函数了