Hbase RowKey 设计
一、引言
HBase由于其存储和读写的高性能,在OLAP即时分析中越来越发挥重要的作用,在易观精细化运营产品–易观方舟也有广泛的应用。作为Nosql数据库的一员,HBase查询只能通过其Rowkey来查询(Rowkey用来表示唯一一行记录),Rowkey设计的优劣直接影响读写性能。HBase中的数据是按照Rowkey的ASCII字典顺序进行全局排序的,有伙伴可能对ASCII字典序印象不够深刻,下面举例说明:
假如有5个Rowkey:”012”, “0”, “123”, “234”, “3”,按ASCII字典排序后的结果为:”0”, “012”, “123”, “234”, “3”。(注:文末附常用ASCII码表)
Rowkey排序时会先比对两个Rowkey的第一个字节,如果相同,然后会比对第二个字节,依次类推… 对比到第X个字节时,已经超出了其中一个Rowkey的长度,短的Rowkey排在前面。
由于HBase是通过Rowkey查询的,一般Rowkey上都会存一些比较关键的检索信息,我们需要提前想好数据具体需要如何查询,根据查询方式进行数据存储格式的设计,要避免做全表扫描,因为效率特别低。
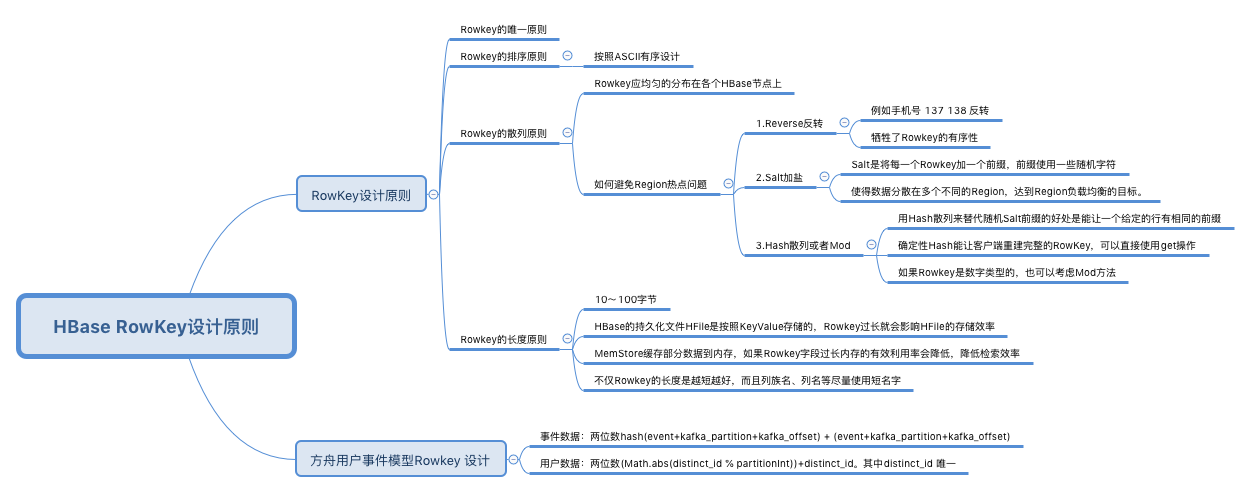
二、Rowkey设计原则
Rowkey设计应遵循以下原则:
1. Rowkey的唯一原则
必须在设计上保证其唯一性。由于在HBase中数据存储是Key-Value形式,若HBase中同一表插入相同Rowkey,则原先的数据会被覆盖掉(如果表的version设置为1的话),所以务必保证Rowkey的唯一性。
2. Rowkey的排序原则
HBase的Rowkey是按照ASCII有序设计的,我们在设计Rowkey时要充分利用这点。比如视频网站上对影片《泰坦尼克号》的弹幕信息,这个弹幕是按照时间倒排序展示视频里,这个时候我们设计的Rowkey要和时间顺序相关。可以使用”Long.MAX_VALUE - 弹幕发表时间”的long 值作为Rowkey 的前缀。
3. Rowkey的散列原则
我们设计的Rowkey应均匀的分布在各个HBase节点上。拿常见的时间戳举例,假如Rowkey是按系统时间戳的方式递增,Rowkey的第一部分如果是时间戳信息的话将造成所有新数据都在一个RegionServer上堆积的热点现象,也就是通常说的Region热点问题, 热点发生在大量的client直接访问集中在个别RegionServer上(访问可能是读,写或者其他操作),导致单个RegionServer机器自身负载过高,引起性能下降甚至Region不可用,常见的是发生jvm full gc或者显示region too busy异常情况,当然这也会影响同一个RegionServer上的其他Region。
Region热点问题
通常有3种办法来解决这个Region热点问题:
ΩΩ1、Reverse反转
针对固定长度的Rowkey反转后存储,这样可以使Rowkey中经常改变的部分放在最前面,可以有效的随机Rowkey。
反转Rowkey的例子通常以手机举例,可以将手机号反转后的字符串作为Rowkey,这样的就避免了以手机号那样比较固定开头(137x、15x等)导致热点问题,
这样做的缺点是牺牲了Rowkey的有序性。
ΩΩ2、Salt加盐
Salting是将每一个Rowkey加一个前缀,前缀使用一些随机字符,使得数据分散在多个不同的Region,达到Region负载均衡的目标。
比如在一个有4个Region(注:以[ ,a)、[a,b)、[b,c)、[c, )为Region起至)的HBase表中,加Salt前的Rowkey:abc001、abc002、abc003
我们分别加上a、b、c前缀,加Salt后Rowkey为:a-abc001、b-abc002、c-abc003
可以看到,加盐前的Rowkey默认会在第2个region中,加盐后的Rowkey数据会分布在3个region中,理论上处理后的吞吐量应是之前的3倍。由于前缀是随机的,读这些数据时需要耗费更多的时间,所以Salt增加了写操作的吞吐量,不过缺点是同时增加了读操作的开销。
ΩΩ3、Hash散列或者Mod
用Hash散列来替代随机Salt前缀的好处是能让一个给定的行有相同的前缀,这在分散了Region负载的同时,使读操作也能够推断。确定性Hash(比如md5后取前4位做前缀)能让客户端重建完整的RowKey,可以使用get操作直接get想要的行。
例如将上述的原始Rowkey经过hash处理,此处我们采用md5散列算法取前4位做前缀,结果如下:
9bf0-abc001(abc001在md5后是9bf049097142c168c38a94c626eddf3d,取前4位是9bf0)
7006-abc002
95e6-abc003
若以前4个字符作为不同分区的起止,上面几个Rowkey数据会分布在3个region中。实际应用场景是当数据量越来越大的时候,这种设计会使得分区之间更加均衡。
如果Rowkey是数字类型的,也可以考虑Mod方法。
4. Rowkey的长度原则
Rowkey长度设计原则:Rowkey是一个二进制,Rowkey的长度被很多开发者建议说设计在10~100个字节,建议是越短越好。
原因有两点:
其一是HBase的持久化文件HFile是按照KeyValue存储的,如果Rowkey过长比如500个字节,1000万列数据光Rowkey就要占用500*1000万=50亿个字节,将近1G数据,这会极大影响HFile的存储效率
其二是MemStore缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低,系统无法缓存更多的数据,这会降低检索效率
需要指出的是不仅Rowkey的长度是越短越好,而且列族名、列名等尽量使用短名字,因为HBase属于列式数据库,这些名字都是会写入到HBase的持久化文件HFile中去,过长的Rowkey、列族、列名都会导致整体的存储量成倍增加。
方舟HBase Rowkey设计实战
在实际的设计中我们可能更多的是结合多种设计方法来实现Rowkey的最优化设计,比如设计订单状态表时使用:Rowkey: reverse(order_id) + (Long.MAX_VALUE – timestamp),这样设计的好处一是通过reverse订单号避免Region热点,二是可以按时间倒排显示。
结合易观方舟使用HBase作为事件(事件指的的终端在APP中发生的行为,比如登录、下单等等统称事件(event))的临时存储(HBase只存储了最近10分钟的热数据)来举例:
设计event事件的Rowkey为:两位随机数Salt + eventId + Date + kafka的Offset
这样设计的好处是:
设计加盐的目的是为了增加查询的并发性,假如Salt的范围是0~n,那我们在查询的时候,可以将数据分为n个split同时做scan操作。经过我们的多次测试验证,增加并发度能够将整体的查询速度提升5~20倍以上。随后的eventId和Date是用来做范围Scan使用的。在我们的查询场景中,大部分都是指定了eventId的,因此我们把eventId放在了第二个位置上,同时呢,eventId的取值有几十个,通过Salt + eventId的方式可以保证不会形成热点。在单机部署版本中,HBase会存储所有的event数据,所以我们把date放在rowkey的第三个位置上以实现按date做scan,批量Scan性能甚至可以做到毫秒级返回。
这样的rowkey设计能够很好的支持如下几个查询场景:
1、全表scan
在这种情况下,我们仍然可以将全表数据切分成n份并发查询,从而实现查询的实时响应。
2、只按照event_id查询
3、按照event_id和date查询
此外易观方舟也使用HBase做用户画像的标签存储方案,存储每个app的用户的人口属性和商业属性等标签信息,由于其设计的更为复杂,后续会另起篇幅详细展开。
最后我们顺带提下HBase的表设计,HBase表设计通常可以是宽表(wide table)模式,即一行包括很多列。同样的信息也可以用高表(tall table)形式存储,通常高表的性能比宽表要高出50%以上,所以推荐大家使用高表来完成表设计。表设计时,我们也应该要考虑HBase数据库的一些特性:
(1)在HBase表中是通过Rowkey的字典序来进行数据排序的
(2)所有存储在HBase表中的数据都是二进制的字节
(3)原子性只在行内保证,HBase不支持跨行事务
(4)列族(Column Family)在表创建之前就要定义好
(5)列族中的列标识(Column Qualifier)可以在表创建完以后动态插入数据时添加
四、总结
在做Rowkey设计时,请先考虑业务是读比写多、还是读比写少,HBase本身是为写优化的,即便是这样,也可能会出现热点问题,而如果我们读比较多的话,除了考虑以上Rowkey设计原则外,还可以考虑HBase的Coprocessor甚至elastic search结合的方法,无论哪种方式,都建议做实际业务场景下数据的压力测试以得到最优结果