分布式 Trace 数据模型
distributed-tracing 数据模型
通过跟踪从前端到后端的交互,通过trace数据,可以扩展现有的错误数据,跟踪软件的性能,测量吞吐量和延迟等指标,并显示跨多个系统的错误影响:
- 出现特定错误事件或问题时发生了什么
- 哪些因素导致应用程序出现瓶颈或延迟问题
- 哪些的endpoint或操作消耗时间最多
什么是追踪?
首先,请注意Trace不是什么:Trace不是分析。尽管概要分析和跟踪的目标有相当多的重叠,虽然它们都可用于诊断应用程序中的问题,但它们在测量的内容和记录数据的方式方面有所不同。
一个Profiler可以测量任何数目的应用程序的操作的各方面的:指令执行数,正在使用的各种处理的内存量,给定的时间的函数调用需要的量,等等。生成的配置文件是这些测量值的统计汇总。
一个tracer工具,在另一方面,侧重于什么事(何时),而不是发生了多少次发生或者花了多长时间。trace的结果是在程序执行期间发生的事件日志,这些事件往往跨越多个系统。就 Sentry 的跟踪而言,总是——包括时间戳,允许计算持续时间,但测量性能并不是它们的唯一目的。它们还可以显示互连系统交互的方式,以及一个系统中的问题可能导致另一个系统出现问题的方式。
(备注:除了测量性能外,还可以做故障的根因分析)
为什么是Trace 模型
应用程序通常由互连的组件组成,这些组件也称为服务。作为一个例子,让我们看一个现代 Web 应用程序,它由以下组件组成,由网络边界分隔:
- 前端(单页应用程序)
- 后端(REST API)
- 任务队列
- 数据库服务器
- Cron 作业调度程序
这些组件中的每一个都可以在不同的平台上以不同的语言编写。每个都可以使用 Sentry SDK 单独检测以捕获错误数据或崩溃报告,但该检测不能提供完整的图片,因为每个部分都是单独考虑的。Trace允许您将所有数据联系在一起。
在我们的示例 Web 应用程序中,跟踪意味着能够跟踪从前端到后端和后端的请求,从请求创建的任何后台任务或通知作业中提取数据。这不仅允许您关联 Sentry 错误报告,查看一个服务中的错误如何传播到另一个服务,而且还允许您更深入地了解哪些服务可能对应用程序的整体性能产生负面影响。
在学习如何在您的应用程序中启用跟踪之前,了解一些关键术语以及它们之间的关系会有所帮助。
关键术语:
Trace
一个Trace代表你要测量或跟踪整个操作的记录-像网页加载,完成您的应用程序在后端的一些动作,或cron作业的用户的一个实例。当跟踪包括多个服务中的工作时,例如上面列出的服务,它被称为分布式跟踪,因为跟踪分布在这些服务中。
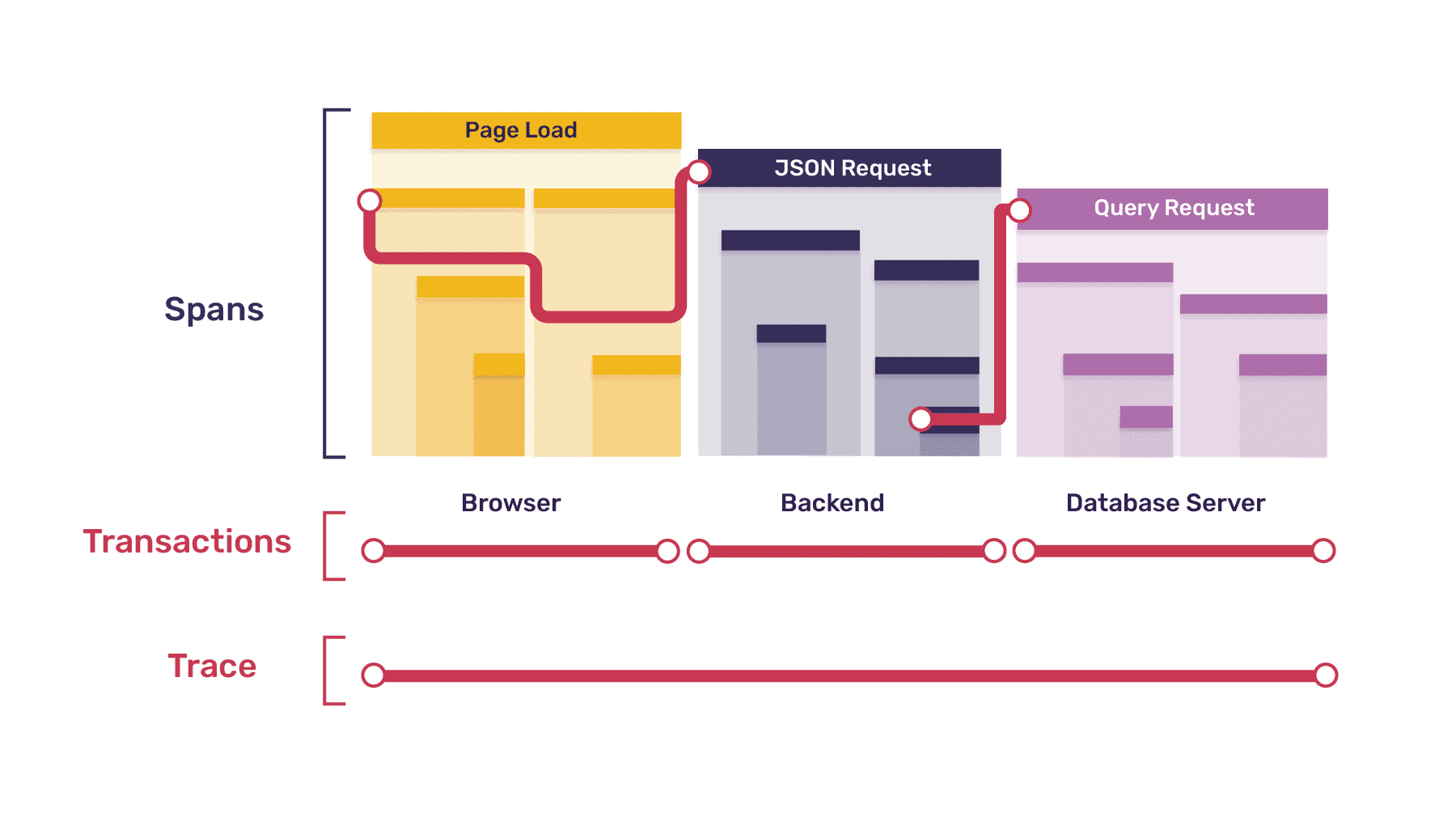
每个Trace由一个或多个称为事务的树状结构组成,其节点称为跨度。在大多数情况下,每个事务代表被调用服务的单个实例,并且该事务中的每个跨度代表该服务执行单个工作单元,无论是调用该服务中的函数还是调用不同的服务。这是一个示例跟踪,分解为事务和跨度:
![]()
由于事务具有树状结构,因此顶级跨度本身可以分解为更小的跨度,这反映了一个函数可能调用许多其他更小的函数的方式;这是使用父子隐喻来表达的,因此每个跨度都可能是多个其他子跨度的父跨度。此外,由于所有树都必须有一个根,因此每个事务中的一个跨度始终代表事务本身,而事务中的所有其他跨度都从该根跨度下降。这是上图中交易之一的放大视图:
![]()
示例:调查缓慢的页面加载
假设您的 Web 应用程序加载缓慢,您想知道原因。要让您的应用程序首先进入可用状态,必须发生很多事情:对后端的多个请求,可能是一些工作 - 包括对数据库或外部 API 的调用 - 在返回响应之前完成,并由浏览器处理以呈现所有将返回的数据转化为对用户有意义的内容。那么这个过程的哪一部分会减慢速度?
假设在这个简化的示例中,当用户在浏览器中加载应用程序时,每个服务中都会发生以下情况:
- 浏览器
- HTML、CSS 和 JavaScript 各 1 个请求
- 1 次渲染任务,触发 2 次 JSON 数据请求 ^
- 后端
- 3 个服务静态文件的请求(HTML、CSS 和 JS)
- 2 个 JSON 数据请求 - 1 个需要调用数据库 - 1 个需要调用外部 API 并在将结果返回到前端之前处理结果^
- 数据库服务器
- 1 个请求需要 2 个查询
- 1 查询以检查身份验证
- 1 查询获取数据
- 1 个请求需要 2 个查询
注意:外部 API 没有准确列出,因为它是外部的,因此您看不到它的内部。
在此示例中,整个页面加载过程,包括上述所有过程,都由单个trace表示。该跟踪将包含以下交易:
- 1 个浏览器事务(用于页面加载)
- 5 个后端事务(每个请求一个)
- 1 个数据库服务器事务(用于单个 DB 请求)
每个事务将被分解为跨度如下:
浏览器页面加载事务
:7 个跨度
- 1 个根跨度代表整个页面加载
- HTML、CSS 和 JS 请求各 1 个(共 3 个)
- 渲染任务的 1 个跨度,它本身包含
- 2 个子跨度,每个 JSON 请求一个
让我们在这里暂停一下以说明一个重点:浏览器事务中此处列出的一些跨度(尽管不是全部)与前面列出的后端事务直接对应。具体来说,浏览器事务中的每个请求跨度都对应于后端中的一个单独的请求事务。在这种情况下,当一个服务的跨度产生了交易的后续服务,我们称之为原始跨度父跨度都在交易,其根跨度。在下图中,波浪线代表这种父子关系。
![]()
在我们的示例中,除了初始浏览器页面加载事务之外的每个事务都是另一个服务中一个跨度的子项,这意味着除了浏览器事务根之外的每个根跨度都有一个父跨度(尽管在不同的服务中)。
在完全检测的系统(其中每个服务都启用了跟踪的系统)中,这种模式将始终适用。唯一的无父跨度将是初始交易的根;每隔一个跨度都会有一个父级。此外,parent和child将始终生活在同一个服务中,除非在子跨度是子交易的根的情况下,在这种情况下,父跨度将生活在调用服务中,而子交易/子根跨度将住在被叫服务中。
换句话说,一个完全检测的系统会创建一个跟踪,它本身就是一个连接的树——每个事务都是一个子树——在这棵树中,子树/事务之间的边界正是服务之间的边界。上图显示了我们示例的完整跟踪树的一个分支。
现在,为了完整起见,回到我们的跨度:
后端 HTML/CSS/JS 请求事务
:每个跨 1 个
- 1 个表示整个请求的根跨度(浏览器跨度的子项)^
带有数据库调用事务的后端请求
:2 个跨度
- 1 个表示整个请求的根跨度(浏览器跨度的子项)
- 用于查询数据库的 1 个跨度(数据库服务器事务的父级)^
带有 API 调用事务的后端请求
:3 个跨度
- 1 个表示整个请求的根跨度(浏览器跨度的子项)
- API 请求的 1 个跨度(与数据库调用不同,不是父跨度,因为 API 是外部的)
- 1个跨度用于处理API数据^
数据库服务器请求事务
:3 个跨度
- 1 个代表整个请求的根跨度(上面后端跨度的子项)
- 1 跨度用于身份验证查询
- 查询检索数据的 1 个跨度
总结一下这个例子:在对所有服务进行检测后,您可能会发现 - 由于某种原因 - 是数据库服务器中的 auth 查询使事情变慢,占整个页面所需时间的一半以上加载过程完成。跟踪无法告诉您为什么会发生这种情况,但至少现在您知道该往哪里看!
数据发送

数据包是以 transaction 为单位进行发送的, transaction包括多个span,多个transaction共享一个trace_id
