即席数据分析中的缓存机制和离线队列机制
每一次ad-hoc查询,均是会占用有限的计算资源,而OLAP 系统在现有技术下,并不能支撑很高的查询并发,为了有效改善这个问题,在查询时间范围内数据未发生变化或者变化量小,有效运用缓存可以有效提高查询效率和用户体验
缓存机制的实现:
对SQL的查询结果进行缓存,可以在 adhoc 层 或者 api 层进行处理
- adhoc/api层可以对Query对象或者SQL进行Hash,hash值设定为缓存的key,计算完成后将查询结果存入 redis(同时需要保存最后计算时间)
- 缓存原则是越底层做合适,但缓存跟业务场景关联性强,比如有的业务场景不允许缓存误差,那么缓存设定在底层就不合适,所以adhoc需要支持多个产品或者业务,可以由api层来做缓存
- 对于已经配置好的看板,可以设置定时任务,每天凌晨可以有调度定时执行查询,查询后根据缓存机制进行缓存
- 预判场景,有些不合适缓存的尽可能不缓存,比如单纯的查明细、结果数据大、数据导出等
- 需要从界面端带一个参数:是否使用缓存,如果为true 表示可以走缓存逻辑,如果为false 则表明是用户强制刷新
- 返回给界面端的response带一个 最后计算时间
缓存有效期
每次进行引擎查询时,固定设置一个N小时的缓存,会导致数据刷新不及时,造成数据理解上的偏差。
比较严重的现象例如: 相同指标在不同图表中的数据不一致,尤其是在同一个DashBoard内时,让人难以理解;
原因在于: 不同的图表在不同时间创建和缓存的,在时间差内,相关的数据发生了变更
有两个方式可以兼容体验和问题,缓解这种现象
1.时间机制
对于时序数据的分析,查询时都是有时间范围的,那么可以
根据时间范围,适当调整缓存时效:
- 图表中相关指标的数据已经不会发生变化,例如查询的时间范围距离现在够久(上月的相关指标,去年的指标),这样的指标缓存几天都没问题,因为数据已经不会发生变更
- 如果相关分析是实时分析当前状态的,比如实时PV,当天分钟级指标,那么缓存机制都不应该加上去
实现方案:对分析条件中的时间进行判断,根据不同场景设置不同的时效
2.数据量变化阈值机制
在数据变更量在一定范围内时,业务上允许介绍一定的误差。假设 分析指标中相关事件从缓存时开始计数,对于的事件pv的变化量 未达到 前7日平均pv 的 1% ,则不进行缓存刷新。
以下为实现方案:
1.数据流处理时,记录每个event 的持续累加次数:(total_pv) 和 过去N日的日pv:(20181201\_pv,20181202\_pv....dayN\_pv)
- 过去N日的平均pv:
avgPV= SUM(day1~n_pv)/N - 缓存的时间点的瞬时pv:
pvx
2.后续在进行查询时,会检索查询条件中所有事件,如果其中任意事件触发以下规则,则清理缓存进行重新查询:
1 | - 假设变化量阀值设为 %1 |
对于任意事件,同样的计算规则,不针对单个事件,对所有事件进行持续累积。
这个机制需要额外的开发工作来支持
- 数据处理过程中的pv值需要缓存起来,且数据流每批次处理需要对所有事件的pv值进行更新,对流处理有一定性能影响
- 每次做分析查询,需要对查询中所包含的全部事件进行检索和规则计算,对查询性能有一定影响,影响小
- 分析查询结果缓存时需要对所有事件的瞬时PV进行查询并且记录redis,对查询性能有一定影响,影响小
方案能降低问题的出现概率,无法完全缓存导致数据不一致的问题,需要在产品层面引导用户;
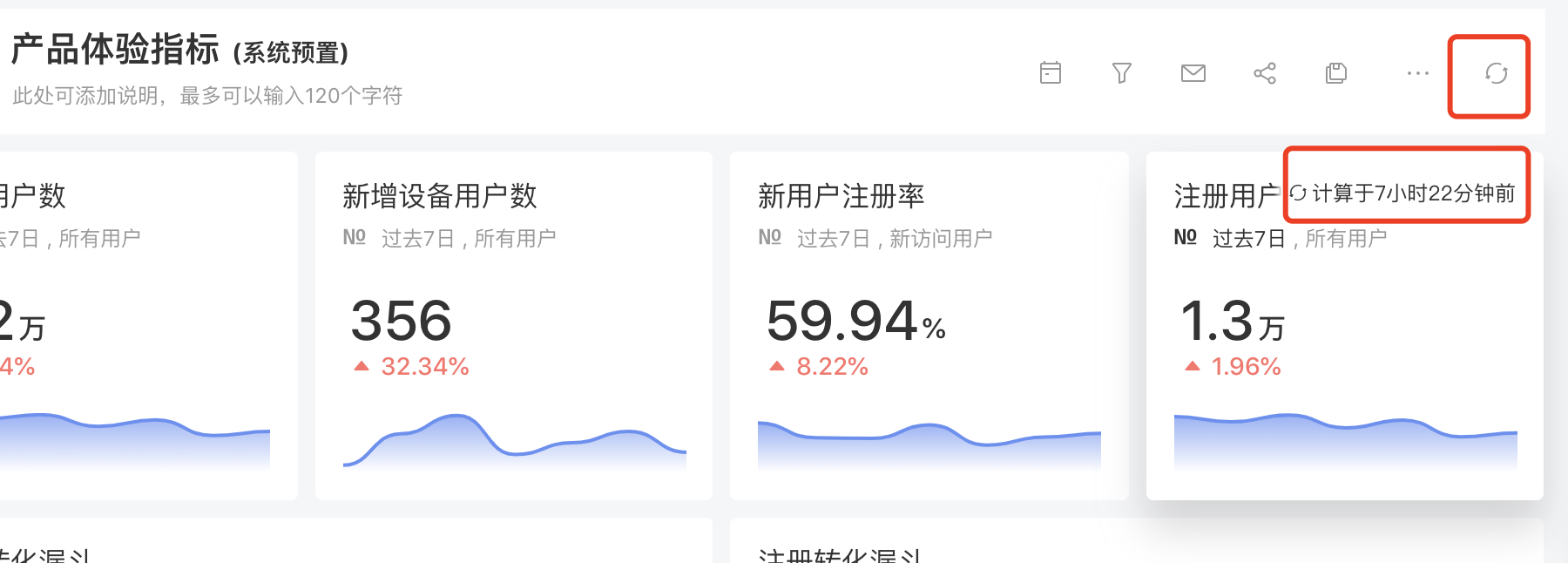
- 有缓存的图表需要加上最后计算时间,可以hover出现。 相较于 同指标数对不上的问题,体验好很多
- 有缓存的图表加一个刷新按钮/图标,强制更新,不走缓存。给用户最新计算结果的选择
- dashboard 可以加一个全局刷新按钮/图标,前段可以从上到下控制并发度强制刷新所有的图表

其他用户体验优化
离线队列
针对慢计算,比如数据量特别大,短时间无法计算出来的,用户在长时间等待后却得到计算超时,则需要设计离线队列。将该查询从即席查转到离线队列,从前台等待,转为后台任务
- 界面端查询等待超过一分钟,主动kill当前查询,转离线队列
- 查询时间跨度超过N天,可以预判是慢sql的
- 历史有相似查询,且查询失败的(比如按高基维度分组)
限制高并发
Presto并不能很好支持高并发的查询计算,尤其是当集群机器数较少,计算任务复杂的情况下。所以需要控制即席查询的并发数,则需要做一个全局的并发度控制,或者全部走离线队列的形式